Model AI NVIDIA baru dengan tiga mode decoding yang unified, hingga 6× lebih cepat dari Qwen3-8B. Performa luar biasa untuk berbagai aplikasi AI.
Peneliti NVIDIA baru saja merilis Nemotron-Labs-Diffusion, keluarga model bahasa yang unik banget. Model ini gabungin tiga mode decoding dalam satu arsitektur yang sama.
Model ini support autoregressive (AR) decoding, diffusion-based parallel decoding, dan self-speculation decoding. Ada dalam ukuran 3B, 8B, dan 14B parameter.
Nemotron-Labs-Diffusion juga punya variant base, instruct, dan vision-language. Jadi kamu bisa pake sesuai kebutuhan aplikasi yang kamu buat.
Advertisement
Slot in-article yang tampil setelah paragraf ketiga.
Model bahasa autoregressive (AR) standar generate teks satu per satu dari kiri ke kanan. Setiap token tergantung dari token sebelumnya.
Ketergantungan sequential ini membatasi paralelisme GPU per step generation. Hasinya, hardware utilization jadi rendah di batch size kecil.
Diffusion language models (LM) pendekatan berbeda. Daripada generate token secara sequential, mereka denoise multiple tokens secara paralel per forward pass.
Tradeoff-nya ada di akurasi: diffusion LM sering ketinggalan AR model di benchmarks, butuh lebih banyak data buat performa yang comparable.
Nemotron-Labs-Diffusion ini di-train dengan joint AR-diffusion objective. Saat inference, model jalan dalam tiga mode tergantung konteks deployment.
Yang unik, gak ada modification arsitektur khusus mode - sama weights dipake untuk ketiga mode ini. Modelnya lebih efisien dan gak boros ruang penyimpanan.
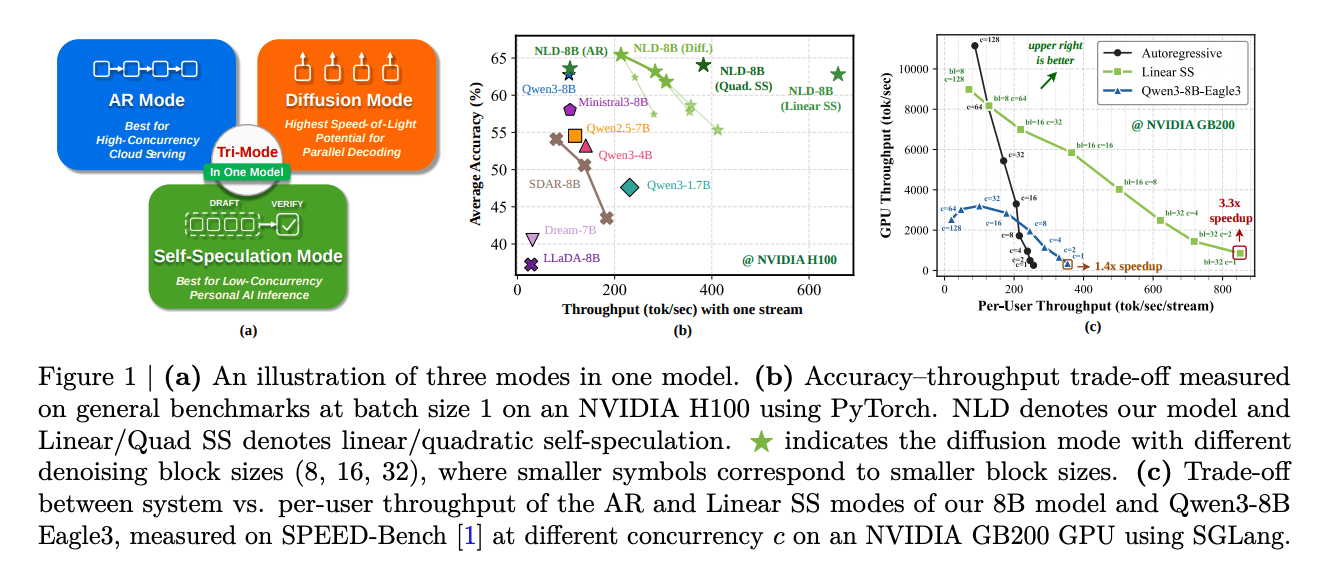
AR mode itu standard left-to-right autoregressive decoding pake causal attention. Mode ini paling cocok untuk high-concurrency cloud serving.
Diffusion mode denoises multiple tokens secara paralel dalam fixed-length block. Sequence di-partisi ke dalam blok-blok kontinyu.
Self-speculation mode pake pathway diffusion buat draft candidate tokens dan pathway AR buat verifikasi mereka, dalam satu model yang sama.
LoRA-enhanced linear self-speculation ini bisa improve tokens per forward (TPF) sampe 14.4%, 32.5%, dan 27.6% di skala 3B, 8B, dan 14B.
Penelitian juga lapor speed-of-light analysis - theoretical upper bound pada tokens per forward pass yang achievable sama diffusion mode.
Di block length 32, SOL acceptance rate rata-rata sampe 7.60×, melebihi 10× di coding dan multilingual tasks. Cuan banget!
Bandingin sama Qwen3-8B: NLD-8B AR mode dapet 63.61% average accuracy, versus 62.75% buat Qwen3-8B dan 58.02% buat Ministral3-8B-Instruct.
NLD-8B diffusion mode dapet 63.18% average accuracy dengan 2.57× TPF. Self-speculation mode dengan LoRA dapet 62.81% accuracy dengan 5.99× TPF.
Di SPEED-Bench dengan SGLang di NVIDIA GB200 GPU, linear self-speculation achieve 4× higher throughput daripada Qwen3-8B.
Model vision-language, Nemotron-Labs-Diffusion-VLM-8B, extend framework yang sama ke multimodal tasks. Sampe 7.45× TPF di responses panjang.
Practical-nya, kamu bisa pake mode tergantung deployment context. High-concurrency API? Pake AR mode. Single-user inference? Self-speculation + LoRA.
Untuk coding, math, multilingual tasks? Self-speculation + LoRA jadi pilihan terbaik. Acceptance lengthnya paling tinggi di konten terstruktur.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→