Teknik baru dari Nous Research ngecepatin training AI dengan 1.4-1.7x speedup untuk context panjang.
Kamu udah tahu nggak? Training model AI dengan sequence panjang itu mahal banget, bro. Biaya perhitungan dan memori naik kuadrat Θ(N²) sama panjang sequence N.
FlashAttention udah ngurangi masalah ini dengan IO-aware tiling, tapi perhitungan dasarnya masih tetap Θ(N²).
Nah, Nous Research sekarang ngeluarin Lighthouse Attention, metode baru yang spesifik buat phase pretraining.
Advertisement
Slot in-article yang tampil setelah paragraf ketiga.
Teknik ini bisa ngecepatin training hingga 1.40× sampai 1.69× dibanding baseline, dengan loss training yang sama atau lebih rendah.
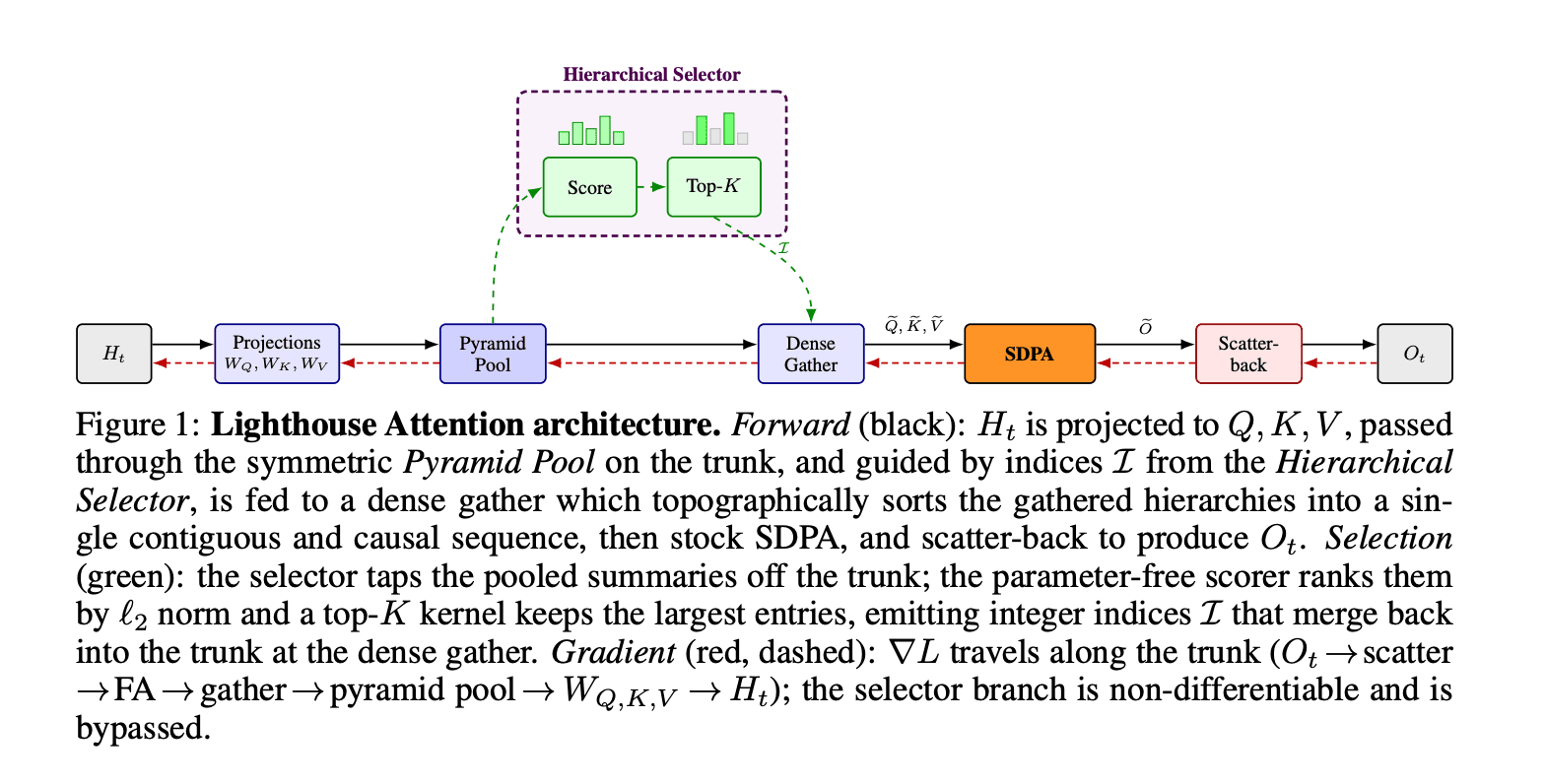
Bedanya dengan metode sebelumnya seperti NSA dan HISA, Lighthouse ini ngincar Q, K, dan V secara simetris.
Metode sebelumnya cuma ngincar K dan V, sementara Q tetap full resolution. Ini bikin perhitungan jadi lebih mahal.
Lighthouse juga punya pipeline empat tahap yang unik. Pertama, average pooling bikin pyramid L-level dari Q, K, dan V.
Di tahap kedua, parameter-free scorer kasih setiap entry pyramid dua skor scalar menggunakan per-head ℓ₂ norms.
Tahap ketiga, selected entries dikumpulin ke sub-sequence yang kontinu dan dense, lalu di-pass ke FlashAttention standar.
Terakhir, setiap output entry di-scatter balik ke base positions-nya via deterministic integer-atomic scatter kernel.
Hasilnya? Di 512K context dengan single NVIDIA B200, Lighthouse 21× lebih cepat di forward pass dan 17.3× lebih cepat di forward+backward.
Penting banget, Lighthouse ini cuma untuk training. Setelah training selesai, modelnya jadi normal dense-attention model untuk inference.
Para peneliti juga pake dua-stage training. Pertama training dengan Lighthouse, lalu resume dengan dense SDPA buat final fine-tuning.
Hasilnya? Semua konfigurasi Lighthouse baseline lebih baik dari dense baseline di token budget yang sama.
Di ablation grid, mereka nemu bahwa pyramid yang lebih dangkal (L=3) konsisten lebih baik dari yang lebih dalam (L=4, L=5).
Konfigurasi terbaik di grid adalah L=3, p=2, k=1536 dengan dilated scorer, dengan final loss 0.6825.
Buat evaluasi retrieval dengan Needle-in-a-Haystack, tiga dari empat konfigurasi Lighthouse match atau baseline lebih baik.
Lighthouse juga bisa scale ke 1M-token training across 32 Blackwell GPUs dengan context parallelism.
Satu-satunya batasan: Lighthouse ini cuma untuk training, buat autoregressive decoding karena mekanismenya berbeda.
Intinya, Lighthouse Attention ini solusi super powerful buat ngecepatin training AI dengan context panjang tanpa mengurangi kualitas model akhir.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→

