Model diffusi pertama dari autoregressive LLM dengan hingga 7.7x kecepatan lebih cepat. Revolusi dalam generasi teks AI dari Zyphra.
Zyphra, lab AI dari San Francisco, baru saja merilis ZAYA1-8B-Diffusion-Preview. Ini adalah preview dari pekerjaan awal mereka dalam model bahasa diffusi.
Model ini membuktikan bahwa model bahasa autoregresif yang sudah ada bisa diubah menjadi model diffusi diskrit tanpa kehilangan performa evaluasi.
Kita perlu tahu dulu kenapa ini penting. Saat ini, kebanyakan model bahasa generatif bekerja dengan cara autoregresif: mereka menghasilkan satu token (kata atau bagian kata) secara berurutan.
Advertisement
Slot in-article yang tampil setelah paragraf ketiga.
Untuk setiap token baru, mekanisme attention harus melihat kembali ke semua token yang sudah dihasilkan sebelumnya. Ini bikin GPU lebih banyak waktu memindahkan data dari memori daripada melakukan perhitungan aktual.
Jadi sistem jadi terbatas oleh bandwidth memori, bukan oleh kemampuan komputasi. Ini masalah karena GPU modern jauh lebih cepat dalam menghitung daripada memindahkan data.
Diffusion menawarkan alternatif yang menarik. Daripada menghasilkan satu token per satu, model diffusi menghasilkan beberapa draf dari N token secara bersamaan.
Karena semua N token dalam satu blok berbagi cache yang sama, operasinya berpindah dari bandwidth-memori terbatas ke komputasi terbatas. Di ZAYA1-8B-Diffusion-Preview spesifik, model melakukan transformasi satu langkah dari mask ke token untuk setiap token dalam blok.
Artinya, model secara langsung memprediksi token yang tidak di-mask dalam satu langkah, bukan secara iteratif denoising. Training model diffusi dari awal itu susah banget, dan ada sedikit resep yang sudah terbukti berhasil.
Zyphra punya dua alasan lebih suka konversi daripada training dari awal: pertama, itu memang susah; kedua, tidak ada keuntungan training dalam mode diffusi karena training sudah terbatas oleh komputasi.
Manfaat diffusi muncul hanya saat inferensi, jadi stack pretraining yang sudah ada bisa dipakai apa adanya. Zyphra membangun resep TiDAR, mengambil checkpoint ZAYA1-8B-base, dan melakukan 600 miliar token tambahan mid-training dengan panjang konteks 32k.
Setelah itu, mereka melakukan 500 miliar token ekstensi konteks native ke 128k, lalu fase fine-tuning supervised diffusi. ZAYA1-8B-Diffusion-Preview adalah model diffusi MoE pertama yang dikonversi dari LLM autoregresif, dan model bahasa diffusi pertama yang dilatih di GPU AMD.
Saat inferensi, ZAYA1-8B-Diffusion-Preview menghasilkan draf 16 token secara bersamaan. Sebagian token ini diterima berdasarkan kriteria sampling yang diambil dari speculative decoding. Keuntungan utamanya adalah model yang sama bertindak sebagai speculator dan verifier dalam satu forward pass.
Ini menghilangkan overhead yang terkait dengan menjalankan dua model terpisah seperti metode tradisional EAGLE atau dFlash. Di regime yang sangat terbatas bandwidth memori, hampir semua token yang diterima mewakili kecepatan gratis atas decoding autoregresif.
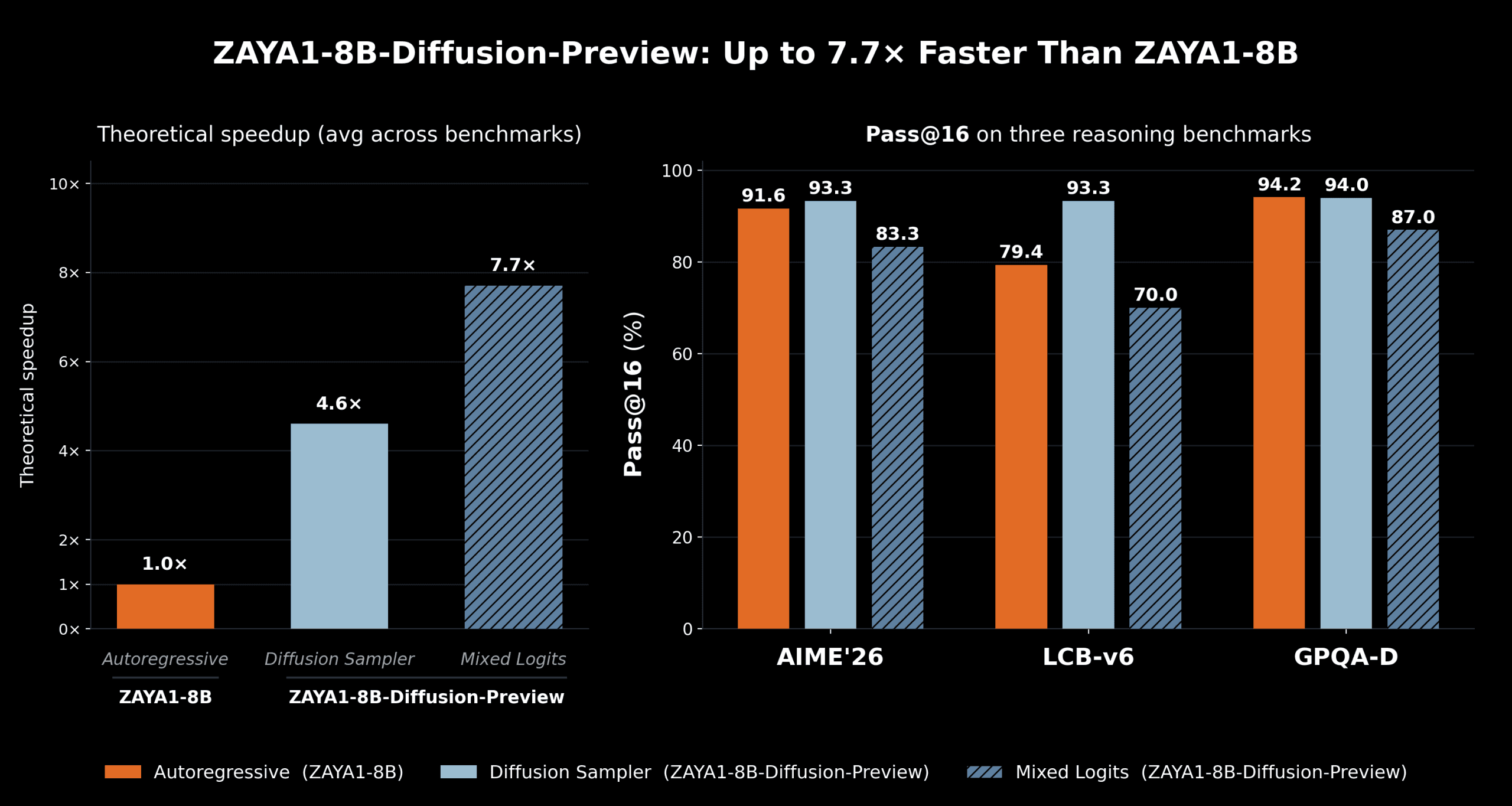
Zyphra melaporkan dua sampler dengan trade-off kecepatan-kualitas berbeda. Sampler diffusi lossless menggunakan kriteria penerimaan speculative decoding standar min(1, p(x)/q(x)), di mana p adalah distribusi logit model autoregresif dan q adalah distribusi model diffusi.
Sampler ini mencapai kecepatan 4.6x tanpa degradasi evaluasi sistematis. Sampler logit-mixing mencampur logits dari speculator diffusi dan model autoregresif, lalu menggunakan distribusi rata-rata untuk verifikasi. Ini meningkatkan tingkat penerimaan karena logits verifikasi lebih dekat ke logits diffusi.
Trade-off antara kecepatan dan kualitas bisa dipilih saat runtime. Penting untuk diingat bahwa karena ZAYA1-8B-Diffusion-Preview adalah checkpoint mid-train yang belum melalui RL training, Zyphra menggunakan evaluasi pass@ daripada benchmark akurasi standar.
ZAYA1-8B-Diffusion-Preview adalah model diffusi speculative satu langkah yang menggunakan pembuatan terbatas urutan. Artinya, model diffusi hanya mampu menghasilkan token dalam subsequence berurutan dimulai dari prefix.
Batasan ini meningkatkan stabilitas training secara drastis dibandingkan dengan tujuan mask diffusi tidak terbatas atau decoding blok set. Model menggunakan varian attention CCA yang sudah ada dari ZAYA1-8B, yang secara drastis mengurangi prefill FLOPs dalam attention.
CCA ini secara langsung bermanfaat untuk diffusi karena diffusi mengubah decoding menjadi operasi yang mirip prefill. CCGQA dengan rasio 4:1 antara kepala query dan key memungkinkan model mendiffuskan lebih banyak token secara paralel sebelum mencapai batas komputasi.
Di hardware AMD MI300x dalam bf16, sistem mendukung sekitar tiga proposal berukuran blok per forward pass tunggal; di MI355x, ini naik menjadi sekitar lima. CCGQA juga beroperasi pada 2x kompresi, yang memungkinkan Zyphra membiayai FLOPs training tambahan yang terkait dengan mid-training TiDAR.
Kapasitas VRAM yang lebih besar dari GPU AMD lebih memungkinkan training diffusi yang lebih efisien secara keseluruhan. Praktiknya, mencapai kecepatan teoretis lebih menantang karena diffusi membawa overhead operasional tambahan dan stack inferensi untuk model diffusi jauh kurang dioptimalkan.
Bagi engineer AI: inferensi terbatas komputasi = penggunaan GPU yang lebih baik saat serving. Bagi tim RL: rollout on-policy yang lebih murah = lebih banyak iterasi RL dengan anggaran hardware yang sama. Bagi arsitek: CCA + CCGQA dirancang bersama untuk diffusi dari awal.
Takeaway praktis: Model diffusi seperti ZAYA1-8B-Diffusion-Preview menawarkan cara revolusioner untuk meningkatkan kecepatan inferensi AI tanpa mengorbankan kualitas output. Ini membuka pintu untuk aplikasi AI yang lebih responsif dan hemat biaya di masa depan.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→